Regular Expression
Some people, when confronted with a problem, think "I know, I'll use regular expressions." Now they have two problems. - Jamie Zawinski
Regular Expressions are difficult to write and maintain. Instead of harping about the problems, I want to explore what Emacs offers to make writing them easier. In particular, I want to tackle the rx macro, the regular s-expression or lispy regular expression.
(require 's) ;; All we need is =s-matches-p= (require 'rx) ;; Creating a regexp that will match -> <File> [<Line>:<Column] <Suggestion> (setq this-file-name "blog.org") (s-matches-p (rx bol (eval this-file-name) space "[" (group (one-or-more digit)) ":" (group (one-or-more digit)) "]" space (group (zero-or-more anything)) eol) "blog.org [17:16] Emacs Lisp, not emacs lisp") ;; Produced regexp, I do not want to write or maintain this by hand "^blog\\.org[[:space:]]\\[\\([[:digit:]]+\\):\\([[:digit:]]+\\)][[:space:]]\\(\\(?:.\\| \\)*\\)$"
Although it is less concise, the example above illustrates the selling point of writing regular expressions at a higher level: it is more understandable, comfortable to write and easier to maintain. Rather, the "lispyness" of the expressions is more appropriate in the style and heart of Emacs, working with symbolic expressions.
The builtin rx macro has no obvious manual but it has a symbol
documentation found via describe-function. For a powerful idea, it
doesn't have strong examples in the wiki or web to promote it. Hackers
before users. To be fair, reading the documentation is enough but
examples or recipes would hasten comprehension. This is what this
article explores, thus the following sections are exploring some
syntax or construct. (Aside, the problems I use are found in Regular
Expression Cookbook and if you found them intriguing, support the
author and buy the book.)
Strings And Quoting
STRING
matches string STRING literally.
CHAR
matches character CHAR literally.
‘(eval FORM)’
evaluate FORM and insert result. If result is a string,
‘regexp-quote’ it.
PROBLEM: What (regular) expression matches this string:
The punctuation characters in the ASCII table are: !"#$%&'()*+,-./:;<=>?@[\]^_`{|}
;; Escape the double quote here (setq input "The punctuation characters in the ASCII table are: !\"#$%&'()*+,-./:;<=>?@[\]^_`{|}") (s-matches-p (rx "The punctuation characters in the ASCII table are: !\"#$%&'()*+,-./:;<=>?@[\]^_`{|}") input) ;; Direct use of strings (not (s-matches-p input input)) ;; Does not work because of quoting (s-matches-p (regexp-quote input) input) (s-matches-p (rx (eval input)) input) ;; More rx
This problem is merely quoting or escaping syntax characters, that is
if you know what those syntax characters are. The function
regexp-quote, which escapes those characters, is simple enough. This
is done by default by rx when a string is passed in for simplicity.
Finally, string variables can be used through the eval syntax, which
is like inserting values with backquoting.
Variables And Ranges
‘(any SET ...)’ ‘(in SET ...)’ ‘(char SET ...)’ matches any character in SET .... SET may be a character or string. Ranges of characters can be specified as ‘A-Z’ in strings. Ranges may also be specified as conses like ‘(?A . ?Z)’. SET may also be the name of a character class: ‘digit’, ‘control’, ‘hex-digit’, ‘blank’, ‘graph’, ‘print’, ‘alnum’, ‘alpha’, ‘ascii’, ‘nonascii’, ‘lower’, ‘punct’, ‘space’, ‘upper’, ‘word’, or one of their synonyms.
PROBLEM: Create one regular expression to match all common misspellings of calendar, so you can find this word in a document without having to trust the author’s spelling ability. Allow an a or e to be used in each of the vowel positions.
(s-matches-p (rx "c" (any "a" "e") "l" (any "a" "e") "nd" (any "a" "e") "r") "celander") (setq misspelling-pattern `(any "a" "e")) (s-matches-p (rx "c" (eval misspelling-pattern) "l" (eval misspelling-pattern) "nd" (eval misspelling-pattern) "r") "calendar") "c[ae]l[ae]nd[ae]r" ;; Generated pattern
Aside from demonstrating a simple range construct, the use of
sub-patterns through the familiar eval allows us to treat these
expressions more modularly, which helps us move away from a monolithic
concatenated string.
PROBLEM: Create a regular expression to match a single hexadecimal character.
(s-matches-p (rx (any "a-f" "A-F" "0-9")) "A") (s-matches-p (rx (in "a-f" "A-F" "0-9")) "A") ;; Equivalently "[0-9A-Fa-f]" ;; Generated pattern (s-matches-p (rx (char hex-digit)) "d") ;; More rx (s-matches-p (rx hex-digit) "d") ;; Equivalently "[[:xdigit:]]" ;; Generated pattern
Lastly, the range syntax allows the familiar dashes to add character
range. Rather, the abstraction of special character ranges like
[:upper:] or [:xdigit:] is nice to know. Other useful constructs
such as word-start, line-end, and punctuation exist that is
worthy to be explored.
Alternatives And Depth
‘(or SEXP1 SEXP2 ...)’ ‘(| SEXP1 SEXP2 ...)’ matches anything that matches SEXP1 or SEXP2, etc. If all args are strings, use ‘regexp-opt’ to optimize the resulting regular expression. ‘(zero-or-one SEXP ...)’ ‘(optional SEXP ...)’ ‘(opt SEXP ...)’ matches zero or one occurrences of A. ‘(and SEXP1 SEXP2 ...)’ ‘(: SEXP1 SEXP2 ...)’ ‘(seq SEXP1 SEXP2 ...)’ ‘(sequence SEXP1 SEXP2 ...)’ matches what SEXP1 matches, followed by what SEXP2 matches, etc. ‘(repeat N SEXP)’ ‘(= N SEXP ...)’ matches N occurrences.
PROBLEM: Create a regular expression that when applied repeatedly to
the text Mary, Jane, and Sue went to Mary's house will match Mary,
Jane, Sue and then Mary again.
(s-match-strings-all (rx (or "Mary" "Jane" "Sue")) "Mary, Jane, and Sue went to Mary's house") ;; Output '(("Mary") ("Jane") ("Sue") ("Mary")) ;; Generated pattern "\\(?:Jane\\|Mary\\|Sue\\)"
This simple problem is a demonstration of using the alternation construct, which is related to ranges and classes. Nothing fancy but the possibility of making it nuanced exist.
PROBLEM: Create a regular expression matching 0 to 255.
(setq range-expression ;; Expression and pattern separated for reuse `(or "0" (sequence "1" (optional digit (optional digit))) (sequence "2" (optional (or (sequence (any "0-4") (optional digit)) (sequence "5" (optional (any "0-5"))) (any "6-9")))) (sequence (any "3-9") (optional digit)))) (setq range-pattern (rx bol (eval range-expression) eol)) ;; A test for the regular expression (require 'cl) (cl-every (lambda (number) (s-matches-p range-pattern (number-to-string number))) (number-sequence 0 255)) ;; Generated pattern "0\\|1\\(?:[[:digit:]][[:digit:]]?\\)?\\|2\\(?:[0-4][[:digit:]]?\\|5[0-5]?\\|[6-9][[:digit:]]?\\)?\\|[3-9][[:digit:]]?" ;; To use this IP Addresses (setq ip4-pattern (rx bol (repeat 3 (sequence (eval range-expression) ".")) (eval range-expression) eol)) (s-matches-p range-pattern "30") (s-matches-p ip4-pattern "300") ;; Testing for permutation might take too long, one is good enough (s-matches-p ip4-pattern "61.12.234.30") ;; Generated pattern "\\(?:\\(?:0\\|1\\(?:[[:digit:]][[:digit:]]?\\)?\\|2\\(?:[0-4][[:digit:]]?\\|5[0-5]?\\|[6-9][[:digit:]]?\\)?\\|[3-9][[:digit:]]?\\)\\.\\)\\{3\\}\\(?:0\\|1\\(?:[[:digit:]][[:digit:]]?\\)?\\|2\\(?:[0-4][[:digit:]]?\\|5[0-5]?\\|[6-9][[:digit:]]?\\)?\\|[3-9][[:digit:]]?\\)"
The idea of this expression is matching the first digit, then
considering the branches. Even if I don't explain in depth, the syntax
should be helpful; but three new constructs deserve some words. First,
the optional or opt syntax is the equivalent of the zero-or-one
construct. Second, the sequence or seq syntax is primarily an
expression wrapper, where a list not an atom is required. Third,
repeat syntax is the same as the repetition construct of a prior
pattern. Regardless of the new syntax, the problem is just flexing the
syntax.
Also, remember to write tests for regular expressions. I made three mistakes on my first draft, thus test before publishing. Strangely, regular expressions are like functions that can be property checked.
Before I forget, the eval construct requires that the variables
exist in the interpreter; meaning, they have to be globally set via
setq before being used. That is why two setters in the snippet set
up the expression and pattern separately and respectively. I suggest
setting the expression or pattern via defconst or defvar as
refactoring. It is unfortunate that let will not work with eval ,
but it isn't a huge cost.
Groups And Backreferencs
‘(submatch SEXP1 SEXP2 ...)’ ‘(group SEXP1 SEXP2 ...)’ like ‘and’, but makes the match accessible with ‘match-end’, ‘match-beginning’, and ‘match-string’. ‘(submatch-n N SEXP1 SEXP2 ...)’ ‘(group-n N SEXP1 SEXP2 ...)’ like ‘group’, but make it an explicitly-numbered group with group number N.
PROBLEM: Create a regular expression that matches any date in yyyy-mm-dd format and separately captures the year, month, and day. As extra challenge, make the groups named.
(setq date-pattern (rx (group-n 3 (repeat 4 digit)) "-" (group-n 2 (repeat 2 digit)) "-" (group-n 1 (repeat 2 digit)))) (s-match-strings-all date-pattern (format-time-string "%F")) ;; Output and pattern, notice it is day, month and year or reverse order "\\(?3:[[:digit:]]\\{4\\}\\)-\\(?2:[[:digit:]]\\{2\\}\\)-\\(?1:[[:digit:]]\\{2\\}\\)" '(("2017-03-30" "30" "03" "2017"))
Capturing groups are fundamental; however, this is where the syntax needs works. Named groups aren't possible here, instead we are limited to numbered groups. Closely, this is not a limitation of the macro but the specific Emacs Lisp regex syntax; a more domain specific version can be tuned. This example just shows not every feature is translated.
The group-n or group syntax is obvious in intention. The first
argument represent the group number and the rest are the actual
expression. Nothing fancy.
PROBLEM: Create a regular expression that matches "magical" dates
in yyyy-mm-dd format. A date is magical if the year minus the century,
the month, and the day of the month are all the same number. For
example, 2008-08-08 is a magical date.
(setq magical-pattern (rx (repeat 2 digit) (group-n 1 (repeat 2 digit)) "-" (backref 1) "-" (backref 1))) (s-matches-p magical-pattern "2008-08-08") ;; Generated pattern "[[:digit:]]\\{2\\}\\(?1:[[:digit:]]\\{2\\}\\)-\\1-\\1"
This just shows backreferences are available. The backref syntax is
just invoking the group with the numeric argument. Again, nothing
complicated.
re-builder
To conclude this exploration, a UI exist for testing and experimenting
on regular expressions: re-builder. Execute the command,
re-builder or regexp-builder, on a buffer containing the text,
then execute reb-change-syntax and select rx. The following
screencast can be illuminating.
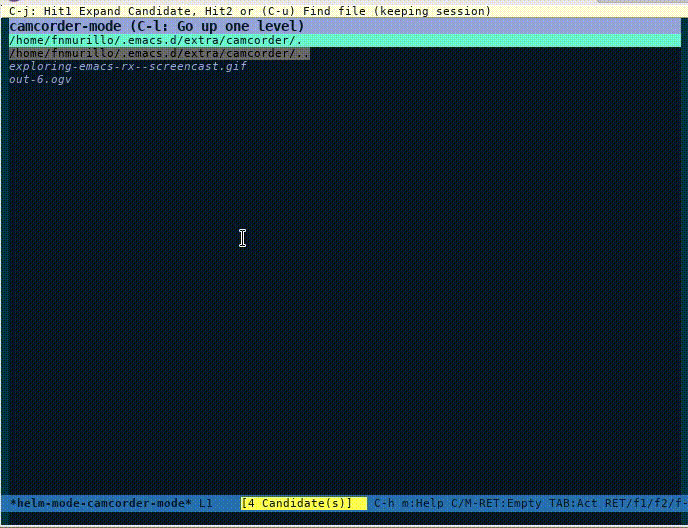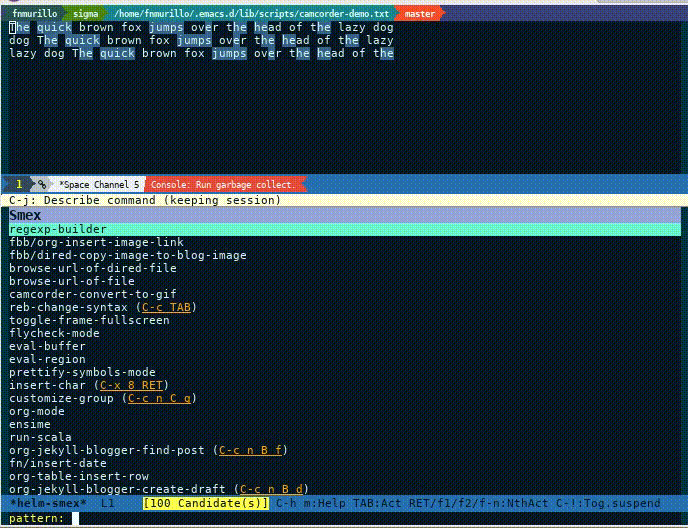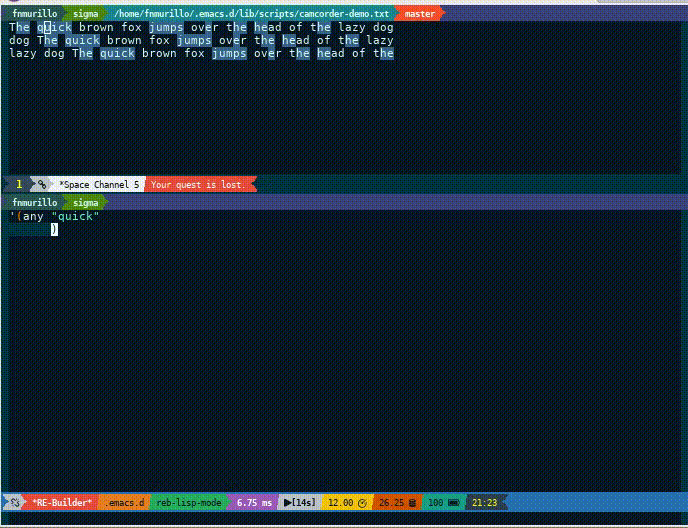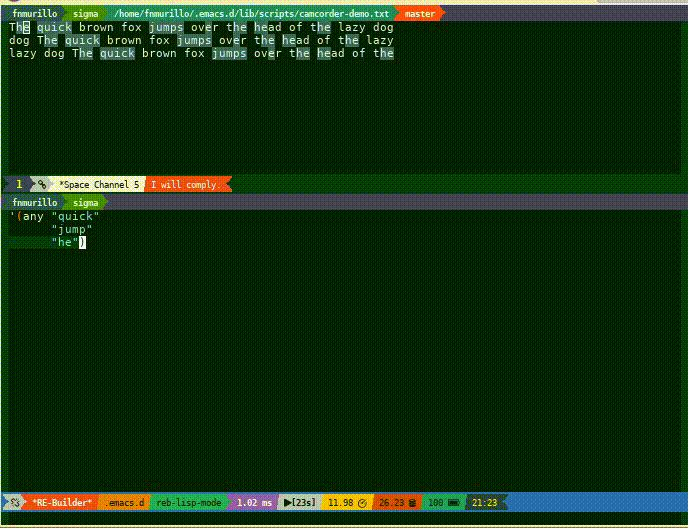
This UI can handle raw expression but we are interested in how this
ties to rx. To elaborate, every time the expression is updated, it
highlights any possible matches. Although it is not as dynamic or
programmatic, it is handy as a quick experiment and check.
Conclusion
This macro is not a replacement for learning regular expressions since there are nuances that a DSL can cover such language specific syntax like PCRE; rather, productivity is the key. As for me, I do not want to write raw regular expression, I would prefer an abstraction to make it easier on the eyes and hands.
Finally, I did not discuss all constructs but only the interesting features that draw me in, and perhaps enchant you as well. Read The Function Documentation.
If this can be done for regular expressions, can it be applied for SQL? An idea still waiting to be written.